字符集
基本概念
字符集(Character Set)定义了如何在数据库中表示和存储字符数据。
字符集是字符编码的集合,字符编码(Encoding)规则规定了一组字符到编码的映射,例如 UTF-8 的字符到 ASCII 码映射规则如下表所示。
表1 UTF-8 字符到 ASCII 码映射
| 字符 | 描述 | ASCII 码 |
|---|---|---|
| 1 | 数字 1 | 49 |
| 2 | 数字 2 | 50 |
| 3 | 数字 3 | 51 |
| 一 | 汉字 1 | 19968 |
| 二 | 汉字 2 | 20108 |
| 三 | 汉字 3 | 19977 |
在 VexDB 数据库中,字符集与编码规则并无实质上的区分,为数据库对象指定字符集时,同时也指定了这些对象的编码规则。
字符集分类
字符集可分为 ASCII 字符集、非 Unicode 字符集与 Unicode 字符集。
- ASCII 字符集:使用 7 比特二进制字符串表示编码,前 3 位+后 4 位支持 128 个字符。例如上表中数字 1 的ASCII 码为 49,通过 hex(49) 换算后,即 0110001,其编码为 0x31。
表2 ASCII 字符集编码- 0 1 2 3 4 5 6 7 0 NUL DLE SP 0 @ P ' p 1 SOH DC1 ! 1 A Q a q 2 STX DC2 " 2 B R b r 3 ETX DC3 # 3 C S c s 4 EOT DC4 $ 4 D T d t 5 ENQ NAK % 5 E U e u 6 ACK SYN & 6 F V f v 7 BEL ETB ' 7 G W g w 8 BS CAN ( 8 H X h x 9 TAB EM ) 9 I Y i y A LF SUB * : J Z j z B VT ESC + ; K [ k { C FF FS , < L \ l | D CR GS - = M ] m } E SO RS . > N ^ n ~ F SI US / ? O _ o DEL - 非 Unicode 字符集:使用一个或多个字节来表示一个字符。例如 GB18030-2022 中,会使用 1 ~ 4 个字节来表示一个字符,大多数中文字符会使用 2 个字节来表示,对于一些特殊的中文字符会使用 4 个字节。
例如在 GBK 环境中,执行以下语句:SELECT bit_length('数智引航');
返回结果为 64,即 16 Bytes * 4。bit_length ------------ 64 (1 row)
若返回结果不为 64,请检查终端、客户端或服务端的字符集配置。 - Unicode 字符集:Unicode 是一个国际标准,支持多种语言的字符。Unicode 使用 1 ~ 4 字节来表示一个字符,例如 UTF-8 中,会使用 3 个字节来表示一个中文字符。
例如在 UTF8 环境中,执行以下语句:SELECT bit_length('数智引航');
返回结果为 96,即 24 Bytes * 4。bit_length ------------ 96 (1 row)
若返回结果不为 96,请检查终端、客户端或服务端的字符集配置。
客户端与服务端字符集
客户端字符集是用户连接数据库的客户端使用的字符集,服务端字符集是数据库实例使用的字符集。此外,如果使用远程连接软件,还需要考虑终端字符集。
- 参数 server_encoding 表示数据库的服务端编码字符集。
- 参数 client_encoding 表示客户端的字符集,可以通过 SET NAMES 语句修改。
- 终端字符集
远程连接软件使用的字符集,需要在连接软件中进行配置。
其中,client_encoding 由用户配置,server_encoding 仅支持在初始化数据库时配置。
客户端与服务端编码转换
若客户端编码为 A,服务器端编码为 B,则需要满足数据库中存在编码格式 A 与 B 的转换。
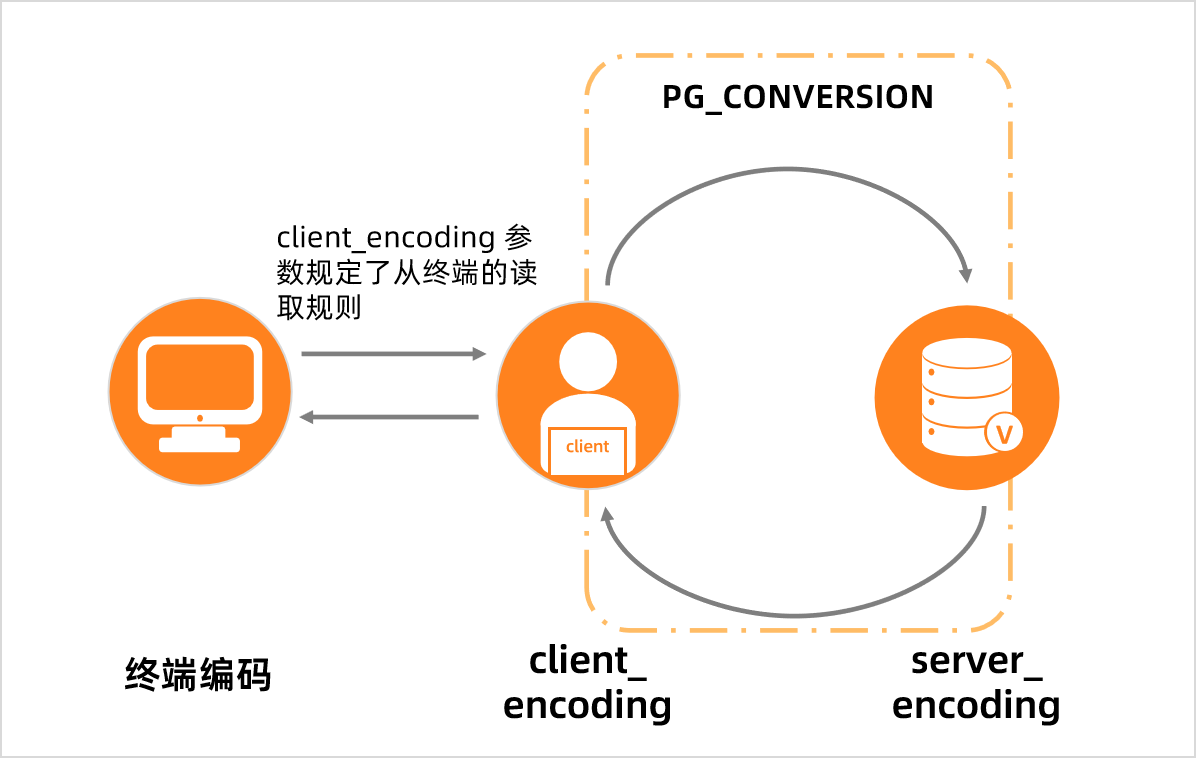
系统表 PG_CONVERSION 记录了 VexDB 数据库支持的字符集转换规则。若无法转换,则建议客户端编码与服务器端编码保持一致,客户端编码可通过GUC 参数 client_encoding 修改。
- 服务端接收到客户端发送的 SQL 语句后,会将其由客户端字符集 client_encoding 向数据库字符集 server_encoding 转换编码。
- 查询结果数据发送到客户端之前也会将数据向客户端字符集 client_encoding 转换编码。
编码转换如下图所示。
说明
使用终端连接数据库时,需要考虑到终端使用的字符集。例如使用 shell 工具连接到数据库服务器时,需要考虑 shell 工具输入的字符集;使用 JDBC 连接数据库时,需要考虑开发环境的字符集等。
例如,使用 JDBC 连接数据库时,VexDB 数据库的字符集为 UTF8,JDBC 连接串设置的字符集为 UTF8,而 java 文件的编码方式为 GBK。则返结果可能不符合预期参见 示例1:使用 JDBC 查询 GBK 编码。
对于以上情况,需要配置连接参数 characterEncoding=gbk 与 allowEncodingChanges=true。其中,characterEncoding 表示 JDBC 客户端的字符集,allowEncodingChanges 表示允许进行终端的字符集的转换。
字符集与字符类型
不同的 client_encoding 编码方式下,向字符类型(如 char 或 nchar)中插入数据,可能会超出长度限制。这是由于终端编码不变的情况下,client_encoding 还表示从终端读取编码的规则。
例如终端编码为 UTF8,client_encoding 为 GBK,则客户端会按 GBK 编码规则读取终端的输入,这可能导致编码读取错误。参见 示例3:不同编码字符集下 char 类型允许存储的字符数量。
形如 char(n) 中的 n 表示存储的字节数量。另外,VexDB 数据库支持形如 char(n character) 的定义方式,通过显式指定 n character,表示存储 n 个字符。
配置方式
VexDB 允许配置数据库级字符集,但不支持修改字符集。
VexDB 支持的字符集列表
表3 VexDB 支持的字符集列表
| 名称 | 描述 | 语言 | 服务端 | 字节/字符 | 别名 |
|---|---|---|---|---|---|
| BIG5 | Big Five | 繁体中文 | 否 | 1-2 | WIN950, Windows950 |
| EUC_CN | 扩展 UNIX 编码-中国 | 简体中文 | 是 | 1-3 | |
| EUC_JP | 扩展 UNIX 编码-日本 | 日文 | 是 | 1-3 | |
| EUC_JIS_2004 | 扩展 UNIX 编码-日本, JIS X 0213 | 日文 | 是 | 1-3 | |
| EUC_KR | 扩展 UNIX 编码-韩国 | 韩文 | 是 | 1-3 | |
| EUC_TW | 扩展 UNIX 编码-台湾 | 繁体中文,中国台湾话 | 是 | 1-3 | |
| GB18030 | 国家标准 | 中文 | 是 | 1-4 | |
| GBK | 扩展国家标准 | 简体中文 | 是 | 1-2 | WIN936, Windows936 |
| BIG5HKSCS | ISO 10646,HKSCS 2016 香港增补字符集 | 繁体中文 | 是 | 1-2 | |
| ISO_8859_5 | ISO 8859-5, ECMA 113 | 拉丁语/西里尔语 | 是 | 1 | |
| ISO_8859_6 | ISO 8859-6, ECMA 114 | 拉丁语/阿拉伯语 | 是 | 1 | |
| ISO_8859_7 | ISO 8859-7, ECMA 118 | 拉丁语/希腊语 | 是 | 1 | |
| ISO_8859_8 | ISO 8859-8, ECMA 121 | 拉丁语/希伯来语 | 是 | 1 | |
| JOHAB | JOHAB | 韩语 | 否 | 1-3 | |
| KOI8R | KOI8-R | 西里尔语(俄语) | 是 | 1 | KOI8 |
| KOI8U | KOI8-U | 西里尔语(乌克兰语) | 是 | 1 | |
| LATIN1 | ISO 8859-1, ECMA 94 | 西欧 | 是 | 1 | ISO88591 |
| LATIN2 | ISO 8859-2, ECMA 94 | 中欧 | 是 | 1 | ISO88592 |
| LATIN3 | ISO 8859-3, ECMA 94 | 南欧 | 是 | 1 | ISO88593 |
| LATIN4 | ISO 8859-4, ECMA 94 | 北欧 | 是 | 1 | ISO88594 |
| LATIN5 | ISO 8859-9, ECMA 128 | 土耳其语 | 是 | 1 | ISO88599 |
| LATIN6 | ISO 8859-10, ECMA 144 | 日耳曼语 | 是 | 1 | ISO885910 |
| LATIN7 | ISO 8859-13 | 波罗的海 | 是 | 1 | ISO885913 |
| LATIN8 | ISO 8859-14 | 凯尔特语 | 是 | 1 | ISO885914 |
| LATIN9 | ISO 8859-15 | 带欧罗巴和口音的 LATIN1 | 是 | 1 | ISO885915 |
| LATIN10 | ISO 8859-16, ASRO SR 14111 | 罗马尼亚语 | 是 | 1 | ISO885916 |
| MULE_INTERNAL | Mule 内部编码 | 多语种编辑器 | 是 | 1-4 | |
| SJIS | Shift JIS | 日语 | 否 | 1-2 | Mskanji, ShiftJIS, WIN932, Windows932 |
| SHIFT_JIS_2004 | Shift JIS, JIS X 0213 | 日语 | 否 | 1-2 | |
| SQL_ASCII | 未指定(见文本) | 任意 | 是 | 1 | |
| UHC | 统一韩语编码 | 韩语 | 否 | 1-2 | WIN949, Windows949 |
| UTF8 | Unicode, 8-bit | 所有 | 是 | 1-4 | Unicode |
| WIN866 | Windows CP866 | 西里尔语 | 是 | 1 | ALT |
| WIN874 | Windows CP874 | 泰语 | 是 | 1 | |
| WIN1250 | Windows CP1250 | 中欧 | 是 | 1 | |
| WIN1251 | Windows CP1251 | 西里尔语 | 是 | 1 | WIN |
| WIN1252 | Windows CP1252 | 西欧 | 是 | 1 | |
| WIN1253 | Windows CP1253 | 希腊语 | 是 | 1 | |
| WIN1254 | Windows CP1254 | 土耳其语 | 是 | 1 | |
| WIN1255 | Windows CP1255 | 希伯来语 | 是 | 1 | |
| WIN1256 | Windows CP1256 | 阿拉伯语 | 是 | 1 | |
| WIN1257 | Windows CP1257 | 波罗的海 | 是 | 1 | |
| WIN1258 | Windows CP1258 | 越南语 | 是 | 1 | ABC, TCVN, TCVN5712, VSCII |
需要注意并非所有的客户端 API 都支持上面列出的字符集。
SQL_ASCII 设置与其他设置不同:如果服务端字符集是 SQL_ASCII,VexDB 会把字节值 0127 根据 ASCII 码进行翻译,而字节值 128255 则会被当作无法解析的字符。如果字符集设置为 SQL_ASCII,就不会进行编码转换。因此,这个设置基本不是用来声明所使用的指定编码,因为该字符集会忽略编码。在大多数情况下,如果使用了任何非 ASCII 编码的数据,则不建议使用 SQL_ASCII 字符集,因为 VexDB 将无法转换或者校验非 ASCII 字符。
- 指定新的数据库字符集编码必须与所选择的本地环境中 LC_COLLATE 与 LC_CTYPE 的设置兼容。
- 当指定的字符编码集为 GBK 时,部分中文生僻字无法直接作为对象名。这是因为 GBK 第二个字节的编码范围在 0x40~0x7E 之间时,字节编码与 ASCII 字符 @A-Z^`a-z{|} 重叠。其中 @^{|} 是数据库中的操作符,直接作为对象名时,会语法报错。例如“侤”字,GBK16 进制编码为 0x8240,第二个字节为 0x40,与 ASCII“@”符号编码相同,因此无法直接作为对象名使用。如果确实要使用,可以在创建和访问对象时,通过增加双引号来规避这个问题。
初始化字符集
在初始化数据库时,VexDB 会根据初始化参数 encoding 配置,默认会选择操作系统的字符集作为初始化字符集。由于 VexDB 安装包文件默认使用 UTF8 编码,因此建议在初始化时指定 locale=UTF8。
在创建数据库时配置字符集
用户可以在数据库创建时指定非缺省编码,但是指定的编码必须与所选的区域相兼容。VexDB 支持通过以下方式在创建数据库时指定字符集:
- 通过命令行指定:
createdb -E GB18030 -T template0 --lc-collate=zh_CN.gb18030 --lc-ctype=zh_CN.gb18030 testdb - 通过 SQL 命令指定:
CREATE DATABASE testdb WITH ENCODING 'GB18030' LC_COLLATE='zh_CN.gb18030' LC_CTYPE='zh_CN.gb18030' TEMPLATE=template0;
上述命令指定 TEMPLATE 为 template0 数据库,指定 TEMPLATE 为其他数据库时,编码和区域设置不能被改变,因为可能导致数据损坏。
数据库的编码存储在 PG_DATABASE 系统表中。 可以使用 vsql 的 -l 选项或 \l 命令列出这些编码。
vsql -l
返回结果如下:
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+------------+------------+-----------------------
postgres | vexdb | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | vexdb | UTF8 | en_US.utf8 | en_US.utf8 | =c/vexdb +
| | | | | vexdb=CTc/vexdb
template1 | vexdb | UTF8 | en_US.utf8 | en_US.utf8 | =c/vexdb +
| | | | | vexdb=CTc/vexdb
vexdb | vexdb | UTF8 | en_US.utf8 | en_US.utf8 |
(5 rows)
示例
示例1:使用 JDBC 查询 GBK 编码
VexDB 数据库的字符集为 UTF8,JDBC 连接串设置的字符集为 UTF8,而 java 文件的编码方式为 GBK 时:
- 执行以下 Java 代码。
import java.sql.*; public class testConn{ static Connection conn = null; static String cname = "com.vexdb.Driver"; static String url = "jdbc:vexdb://xxx.xxx.xxx.xx:xxxx/postgres?loggerLevel=OFF&characterEncoding=gbk&allowEncodingChanges=true"; static String username = "vbadmin"; static String passwd = "VBase@123"; // coded in GBK public static void main(String[] args){ try{ Class.forName(cname); conn = DriverManager.getConnection(url,username,passwd); System.out.println("[SUCCESS] conn database success.\n"); PreparedStatement pstmt = conn.prepareStatement("SELECT bit_length('数智引航')"); pstmt.setFetchSize(1); ResultSet rs = pstmt.executeQuery(); while (rs.next()) { System.out.println("bit_length\n----------\n" + rs.getInt(1) + "\n"); } }catch (Exception e){ System.out.println("[FAIL] conn database fail." + e.getMessage()); } } public void disConn(Connection conn) throws SQLException{ if(conn != null){ conn.close(); } } }
返回结果为 192,不符合预期(4 * 16 Bytes):bit_length ---------- 192
修改连接参数后,重新执行以上代码。static String url = "jdbc:vexdb://xxx.xxx.xxx.xx:xxxx/postgres?loggerLevel=OFF&characterEncoding=gbk&allowEncodingChanges=true";
返回结果如下,符合预期:bit_length ---------- 64
示例2:使用 dump 函数查看编码
前提条件:在终端、服务端字符集为 utf8 环境执行以下操作。
- 设置 client_encoding 为 UTF-8。
SET client_encoding = 'utf8'; - 使用 dump 函数,查看 '数智引航' 的编码。
SELECT dump('数智引航');
返回结果如下,共计 12 字节,因此占用 4 个字符:dump --------------------------------------------------------------- Typ=1 Len=12: 230 181 183 233 135 143 230 149 176 230 141 174 (1 row) - 设置 client_encoding 为 GBK。
SET client_encoding = 'gbk'; - 再次使用 dump 函数,查看 '数智引航' 的编码。
SELECT dump('数智引航');
返回结果如下,共计 18 字节,因此占 6 个字符:dump --------------------------------------------------------------------------------------- Typ=1 Len=18: 229 168 180 231 131 189 229 153 186 233 143 129 231 137 136 229 181 129 (1 row)
示例3:不同编码字符集下 char 类型允许存储的字符数量
前提条件:在终端、服务端字符集为 utf8 环境执行以下操作。
- 创建测试表。
CREATE TABLE chrset(c1 char(4 character)); - 设置当前客户端字符集为 utf8,向表中插入数据。
SET client_encoding = 'utf8'; INSERT INTO chrset values('数智引航');
插入成功:INSERT 0 1 - 再设置当前客户端字符集为 GBK,向表中插入数据。
SET client_encoding = 'gbk'; INSERT INTO chrset values('数智引航');
插入失败,报错插入值长度超过了 char(4) 的限制。ERROR: value too long for type character(4) CONTEXT: referenced column: c1 - 修改表列定义,将 char(4 character) 列修改为 char(6 character)。
ALTER TABLE chrset ALTER c1 TYPE char(6 character); - 重新向表中插入数据。
INSERT INTO chrset values('数智引航');
返回结果如下,表示插入成功。INSERT 0 1
