Graph_Index 索引
Graph_Index索引通过构建一个多层次的图结构,利用图中节点的邻近关系,快速定位到离查询向量最近的向量节点。
Graph_Index是基于传统HNSW索引优化后得到的一种图索引,它解决了原生HNSW索引内存占用过高的问题。使用图索引的场景下,更推荐选择Graph_Index。
Graph_Index与原生HNSW
传统的HNSW索引为了获得更好的查询性能,用更多的内存来存储额外的结构和信息,以实现快速且准确的近似最近邻搜索。例如:对于1000w数据量1024维索引,最低存储空间占用大小甚至高达150GB到300GB,因此,过高的内存占用是原生HNSW索引最显著的缺点。
为了解决这一问题,Graph_Index从以下角度对原生HNSW进行了改良:
- 引入缓存机制,大幅度降低了对机器规格的内存要求。
使用vector_buffers存储向量部分的缓存数据,使用shared_buffers存储邻边关系和元数据等信息。向量索引上的增删改查操作均直接与缓存交互,不产生任何额外的内存申请消耗。
在同时使用多个向量索引的情况下,Graph_Index能够根据使用情况分配不同大小的缓存给各个索引,有助于进一步减少资源占用。 - 动态获取距离计算函数,根据当前机器架构选择最优计算指令集,不强制要求机器规格的指令集支持。
并且,由于采取了向量的缓存措施,所有向量都有专门的内存对齐适配,进一步优化计算指令集使用,加速索引操作。
原理介绍
Graph_Index通过构造多层图结构来近似表示数据的分布。每个节点代表一个数据点,节点间连接的线表示数据点之间的相似性或距离。通过遍历这个图,我们可以快速找到与给定数据相似的邻居。在图结构中进行最近邻查找,可以实现比聚类算法更高的查询加速比。
搜索过程
在创建索引时构建一个初始的图,然后随着向量数据的插入不断完善优化这个多层图结构,使得相似的数据点在图中更加接近。
在搜索阶段,算法从顶层的起始点开始沿着图中的边逐步扩散,直到找到足够多的近似最近邻。
- 顶层是查询的开始层,包含较少的节点,包含最长的链接。上层充当快速到达(接近)目标位置的导航,在深入更密集的更低层进行细致搜索之前,将搜索引导到更接近目标的位置。随着搜索向下层移动,链接长度变得越来越短,顶点数量越来越多。
- 第一次搜索其邻居点,把它们按距离目标的远近顺序存储在定长的动态列表中。之后的每一次查找,依次取出动态列表中的点,搜索其邻居点,将这些新探索的邻居点插入动态列表,每次插入动态列表时需要重新排序,保留前 N 个。如果列表有变化则继续查找,不断迭代直至达到稳态,然后以动态列表中的第一个点作为下一层的入口点,进入下一层。
- 重复上述过程,在每一层使用贪心算法遍历完候选列表中的顶点以及它们的邻居点后,达到最底层。我们将找不到比当前顶点更近的顶点,这是一个局部最小值,也是搜索的停止条件。
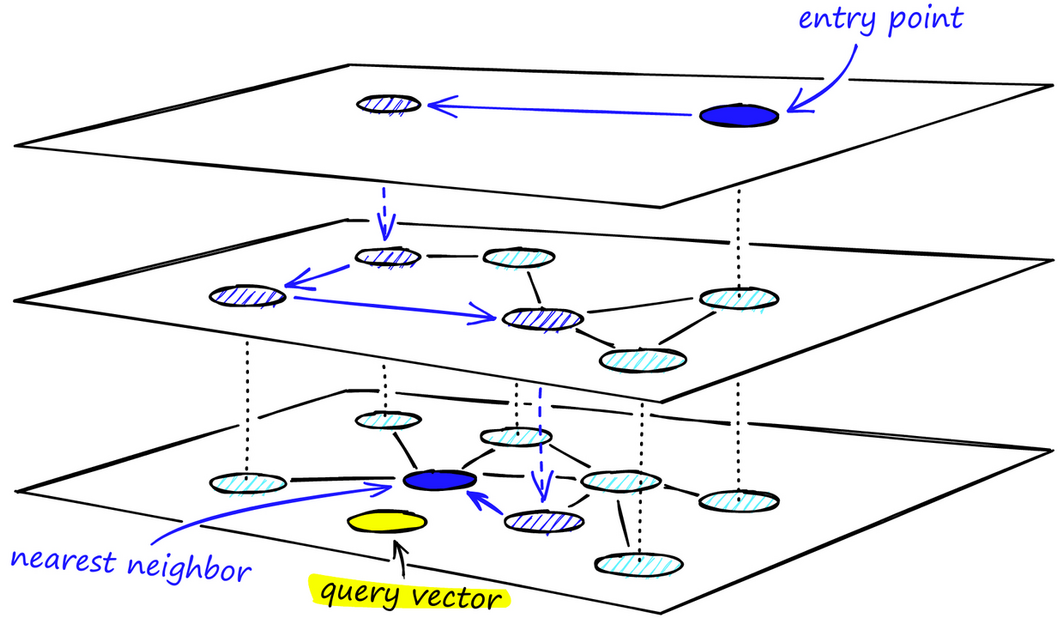
多层图的构建过程
- 在图的构建过程中,向量逐个进行插入。向量在每一层的插入的概率由一个函数决定,对于每个层(除了第 0 层),概率函数都会重复一次。将向量添加到其插入层以及下面的每一层。
- 图的构建从顶层开始。在进入图之后,通过贪心算法遍历图,找到与我们插入的向量最近的 ef 个最近邻顶点,此时 ef = 1。
- 在找到局部最小值(距离插入向量最近的连接顶点)之后,它转移到下一层(与搜索过程中所做的一样)。重复这个过程,直到到达我们选择的插入层。这里开始了第二阶段的构建。
- ef 值增加到 ef_Construction(索引构建参数),意味着将返回更多的最近邻顶点。在第二阶段,这些最近邻顶点成为与新插入的元素 q 的链接的候选顶点,也是下一层的入口点。从这些候选顶点中选择M个最近邻作为链接顶点。
- 经过多次迭代之后,当添加链接时,还会考虑参数 m(定义一个顶点可以拥有的最大链接数)。需要设置合适的 m 值以平衡搜索的召回率和性能。
- 插入的停止条件是在第 0 层中找到局部最小值。
支持向量量化
向量量化是一种将高精度向量映射为低精度向量的技术。其核心思想是用“代表性”的向量(称为“码字”)来代表一个区域内的所有向量,从而用码字的索引代替原始向量,实现数据压缩。通过将高维向量降维并压缩成紧凑的编码,实现快速、高效的近似最近邻搜索。
为了继续改善Graph_Index索引的搜索效率,Graph_Index从V3.0.0.1开始支持了两种向量量化方法,分别是PQ量化和RaBitQ量化。与非量化索引相比,量化通过压缩向量减少了磁盘和内存占用。在构建向量时,可以通过索引构建参数quantizer=pq或者quantizer=rabitq来指定索引的量化方法。
开启向量量化后:
- 会小幅增加索引建立时间;
- 可能因为计算精度的损失导致召回率下降。
- 在表初始数据量小于3840条时,不支持进行向量量化。即便创建索引时指定了quantizer参数,仍会退化为原始Graph_Index索引。且即使后续插入了足够数量的数据,也不会自动计算。
- PQ量化和RaBitQ量化对比:
维度\量化方法 PQ 量化 RaBitQ 量化 空间占用 量化后占用的存储空间约为原始向量的1/4 量化后占用的存储空间约为原始向量的1/2 搜索速度 查询速度略降低,约为原始向量的0.8~1倍 查询速度提升约为原始向量的1.3倍 搜索精度 精度略微降低,受具体数据场景影响 精度有极低幅度降低,受具体场景影响小
PQ量化
PQ(Product Quantization)即乘积量化。在[IVFPQ]((/docs/user-guide/ivfpq)索引的原理介绍中,已经详细解释了利用PQ算法处理一个向量时的基本流程。经过PQ量化处理的索引仅存储了码本、码字以及码字索引,在利用改索引进行向量检索时:先依据查询向量和码本预计算好距离表,然后通过数据库中存储的码字索引快速查表、累加距离,从而找到最近邻。
使用示例:创建Graph_Index索引时指定PQ量化。
CREATE INDEX idx ON t1 using graph_index(embedding) WITH (m=5, ef_construction=10, quantizer=pq, parallel_workers=10);
RaBitQ量化
RaBitQ,全称为Randomly transformed bi-valued vectors for quantizing data vectors,是一种新型的二值(Binary)量化方法。RabBitQ以bit为单位进行量化压缩和距离估算,通过将向量每一维压缩为1-bit二进制串(0或1),实现高达32倍的内存压缩。与传统的PQ量化相比,RaBitQ能在极高压缩比的前提下达到高精度和高性能的效果。
RabitQ的工作原理如下:
- RabitQ量化
向量图索引构建时,RaBitQ使用K-means算法对采样数据聚类,产生聚类质心centroids,以离原始向量最近的质心为基准对原始向量进行归一化,使归一化后的单位向量均匀分布于单位超球面上,则超球体内部的高维超立方体的顶点自然成为RaBitQ的Codebook码本,再将归一化的单位向量映射到超立方体的最近顶点,对于这样的顶点向量,即可用1-bit来表示每一个维度数据,也就得到了RaBitQ量化数据,此外可以通过扩展bits位数额外量化更多信息,以提供更高的召回率。在此期间,通过随机正交矩阵对向量、质心和码本进行旋转,注入随机性,消除一些特定分布上的偏移,使RaBitQ计算结果更稳定。此外,会通过一些预计算提前存储一些中间数据,为后续简化向量检索时的距离估算做准备。 说明
说明为了尽可能提高查询效率,RaBitQ未使用全精度向量进行距离计算,因此不保证返回查询结果集的严格有序,但实际场景下出现向量返回错误顺序的概率极低。
- 距离估算
RaBitQ算法构造了一套经过理论验证的无偏估计方法,用于估算查询向量和量化索引向量的距离,在达到最小化误差的基础上,保障了高召回率。
①预计算
在向量图索引进行构建或数据插入阶段,利用RaBitQ算法对原始向量进行压缩,得到RaBitQ量化数据,并预计算出用于后续向量距离估算所需要的大部分数据和误差因子,将这些数据持久化(不包含原始向量)。
②向量检索
在向量图索引检索阶段,预先将量化的和预计算的数据缓存,并充分利用SIMD指令集进行计算,尽可能高效地估算出距离,达到提高检索效率的目的。
使用示例:创建Graph_Index索引时指定RaBitQ量化。
CREATE INDEX idx USING graph_index(embedding) WITH (parallel_workers=16,ef_construction=200,quantizer=rabitq);
索引参数
索引构建参数
| 参数名称 | 取值说明 | 参数描述 |
|---|---|---|
| m | 取值范围:2~100 默认值:16 | 每个顶点/节点与其最近邻居的最大连接数。 |
| ef_construction | 取值范围:4~1000 默认值:64 | 控制索引构建过程中使用的候选列表的大小。 |
| parallel_workers | 取值范围:0~64 默认值:0 | 并行构建参数,构建索引并行计算线程数。 从V3.0.0.1开始支持并行VACUUM。自动或者手动触发索引的VACUUM行为时,会额外启用当前参数值个数的的后端线程参与VACUUM过程。(单个索引并行构建/VACUUM的最大并行线程数为64,这个值不受参数max_background_workers影响。) |
| quantizer | 取值范围: pq/rabitq | 指定索引量化的方法。 |
GUC查询参数
| 参数名称 | 取值说明 | 参数描述 |
|---|---|---|
| hnsw_ef_search | 取值范围:1~32767 默认值:100 | 会话级参数,表示索引搜索过程中将考虑的最大候选邻居数。数值越高召回越精确,检索越慢。 实际生效值是top-k(查询的limit n)和hnsw_ef_search中更大的值。 |
索引构建操作符
| 索引操作符 | 操作符描述 |
|---|---|
| floatvector_cosine_ops | 计算向量的余弦距离。 |
| floatvector_l2_ops | 计算向量的欧几里得距离。 |
| floatvector_ip_ops | 计算向量的内积。 |
上述参数在索引构建阶段和向量查询阶段的具体使用方式,可参考使用示例。
使用建议
- 设置合适的 maintenance_work_mem 和 max_process_memory 值有利于索引构建速度的增快,当 maintenance_work_mem 不合适时会出现如下提示:
NOTICE: hnsw graph no longer fits into maintenance_work_mem after XXXXX tuples DETAIL: Building will take significantly more time. HINT: Increase maintenance_work_mem to speed up builds - 注意不要将 maintenance_work_mem 设置得太高,以免耗尽服务器的内存。
- max_process_memory 参数必须大于 maintenance_work_mem。
- 建立索引后如果数据变化(删除、更新)较多, 死元组数大于候选队列数,可能导致查询结果变少,建议每更新 40%~60% 数据重建一次索引。
- 当需要提升索引构建速度, 可以适当增大 parallel_workers,建议设置为机器CPU核数的 75% ,最大值 64。
- 当需要提升查询召回率时, 可考虑以下措施:
- 适当增大 m,m 越大越有利于提高召回率,构建索引越慢,查询越慢,插入索引速度越慢。
- 增大 ef_construction,ef_construction 越大越有利于提高召回率,构建索引越慢,插入索引速度越慢。
- 增大 hnsw_ef_search,hnsw_ef_search越大,召回率越高但相应的查询延时会变高。
- 如果向量检索时,查询未按照预期走索引,请参考向量查询不走索引中介绍的内容进行排查,确认查询是否满足走索引的条件。
使用示例
- 数据准备:创建生成随机向量的函数。
CREATE OR REPLACE FUNCTION random_array(dim integer,min_value int, max_value int) RETURNS text AS $$ SELECT REGEXP_REPLACE(REGEXP_REPLACE(array_agg(round(random()* (max_value - min_value + 1) + min_value,3))::text,'{','['),'}',']') FROM generate_series(1, dim); $$ LANGUAGE SQL VOLATILE COST 1; - 创建含向量类型字段的测试表,并插入测试数据。
drop table if exists t_1194690; CREATE TABLE t_1194690(id BIGINT, v floatVECTOR(15)); INSERT INTO t_1194690 SELECT i, random_array(15,1,3)::floatvector(15) FROM generate_series(1, 10000) AS i; - 创建graph_index索引。
- 按余弦距离构建索引:
CREATE INDEX idx_1194690a ON t_1194690 USING graph_index(v floatvector_cosine_ops) WITH(m=16,ef_construction=64, parallel_workers=1); - 按欧几里得距离构建索引:
CREATE INDEX idx_1194690b ON t_1194690 USING graph_index(v floatvector_l2_ops) WITH(m=16,ef_construction=64, parallel_workers=1); - 按内积构建索引:
CREATE INDEX idx_1194690c ON t_1194690 USING graph_index(v floatvector_ip_ops) WITH(m=16,ef_construction=64, parallel_workers=1);
索引构建参数也可省略,此时参数设置为默认值:CREATE INDEX idx_1194690d ON t_1194690 USING graph_index(v floatvector_ip_ops);
- 按余弦距离构建索引:
- 进行向量相似性搜索。
设置查询参数:set hnsw_ef_search = 100;- 按余弦距离排序:
SELECT * FROM t_1194690 ORDER BY v <=> '[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]'::floatvector LIMIT 10; - 按欧几里得距离排序:
SELECT * FROM t_1194690 ORDER BY v <-> '[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]'::floatvector LIMIT 10; - 按内积排序:
SELECT * FROM t_1194690 ORDER BY v <#> '[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]'::floatvector LIMIT 10;
- 按余弦距离排序:
